Flattening Hierarchies with Policy Bootstrapping
John L. Zhou and Jonathan C. Kao
University of California, Los Angeles
Subgoal Advantage-Weighted policy bootstrapping (SAW) is an offline goal-conditioned RL algorithm that scales to complex, long-horizon tasks without needing hierarchical policies or generative subgoal models.
What are the benefits of hierarchies in offline RL?
Goal-conditioned hierarchies achieve state-of-the-art performance on long-horizon tasks, but require a lot of design complexity and a generative model over the subgoal space, which is expensive to train. We do a deep dive into a state-of-the-art hierarchical method for offline goal-conditioned RL and identify a simple yet key reason for its success: it's just easier to train policies for short-horizon goals!
- Prior work makes the argument that combining sparse rewards, discounting, and distant goals makes it very difficult to compare the values of nearby states, and that mitigating this low "value signal-to-noise ratio" is a key benefit of hierarchies.
- However, we find that clearer advantage signals are not enough to close the performance gap.
- The reason is simple: dataset state-action pairs are far more likely to be near-optimal with respect to nearby goals, due to the compounding likelihood of suboptimal "detours" as the trajectory horizon increases.
- Even with clear advantage signals and hindsight goal relabeling, it is difficult to find good state-action-goal tuples on which to train.
Hierarchies bootstrap on policies
How do hierarchical methods solve this issue? They exploit the inductive bias that actions which are good for reaching (good) subgoals are also good for reaching the final goal, as well as the relative ease of training policies only on nearby goals, which we call subpolicies (functionally identical to the low-level actor, but for non-hierarchical policies).
- Hierarchical policies perform test-time bootstrapping: in RL, bootstrapping uses one estimate to update another estimate.
- We can think of policies as estimates of the optimal action distribution, and use policies conditioned on (good) subgoals as target estimates for the policy conditioned on the full goal!
- Rather than update another policy, hierarchies directly sample from the target subgoal-conditioned policy at test time.
- Instead, we could use a subgoal generator to retrieve a subgoal-conditioned policy, and regress a full, flat goal-conditioned policy towards the resulting action distribution during training — similar to prior work in online GCRL.
Algorithm
However, requiring an expensive generative model for subgoals means that we suffer all the costs and limitations of hierarchical methods. Instead, we look at hierarchical policy optimization from the perspective of probabilistic inference, allowing us to (1) unify existing methods and (2) replace explicit subgoal generation with an importance weight over future states.
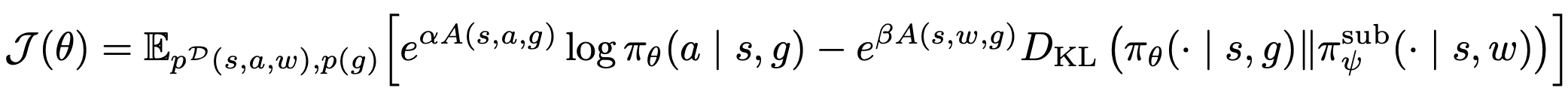
Our method, Subgoal Advantage-Weighted policy bootstrapping (SAW), combines two learning signals into a single objective: the one-step advantage signal from the goal-conditioned value function, and the subpolicy's estimate of the optimal action distribution for the a given subgoal. Rather than explicitly generate subgoals, we instead sample waypoints directly from the same trajectory as the initial state-action pair and weight the contribution of the KL divergence term by the optimality of that waypoint.
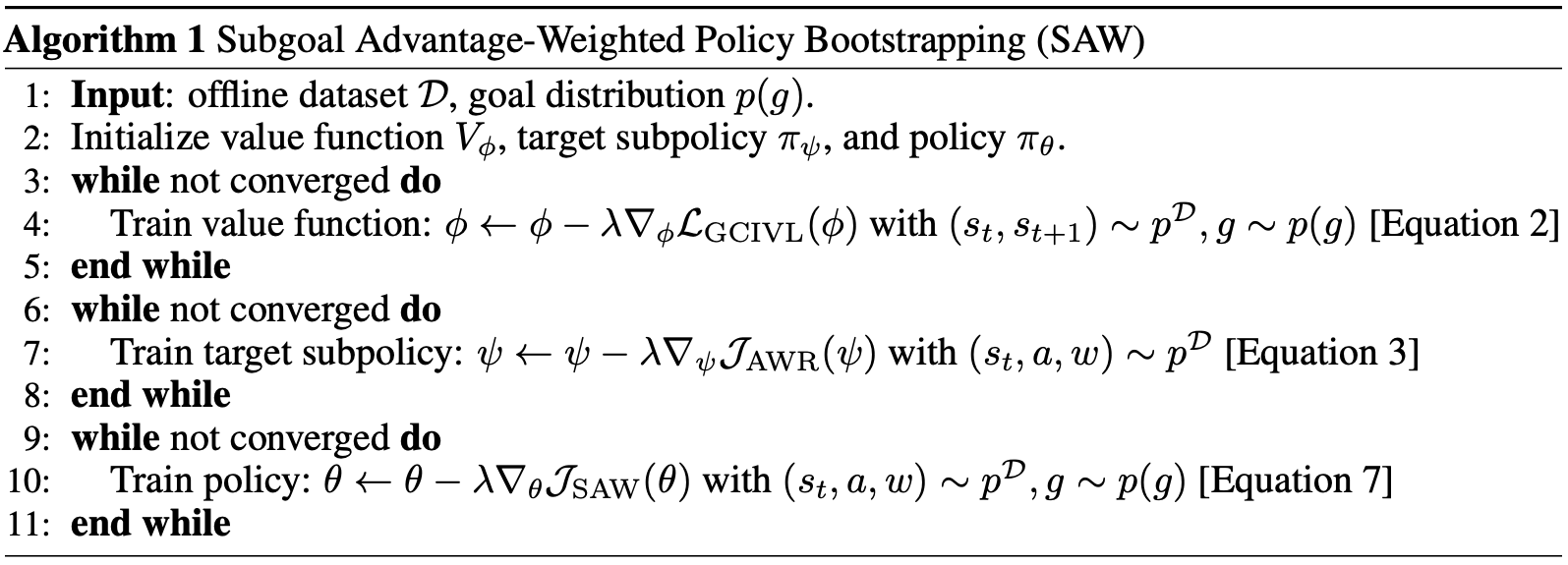
Our training recipe is simple: we train a goal-conditioned value function and a subpolicy on nearby goals in a fashion identical to the low-level actor in hierarchical methods. Then, we train the full flat goal-conditioned policy on goals of all horizons, by sampling states, actions, waypoints, and goals all from the same trajectory.
Experiments

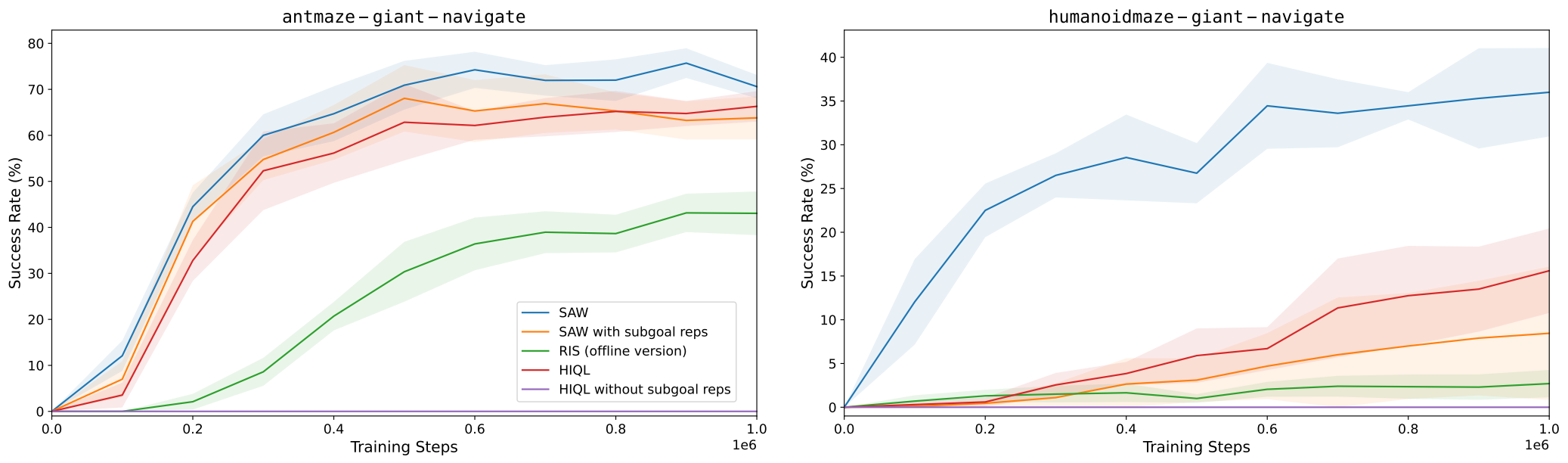
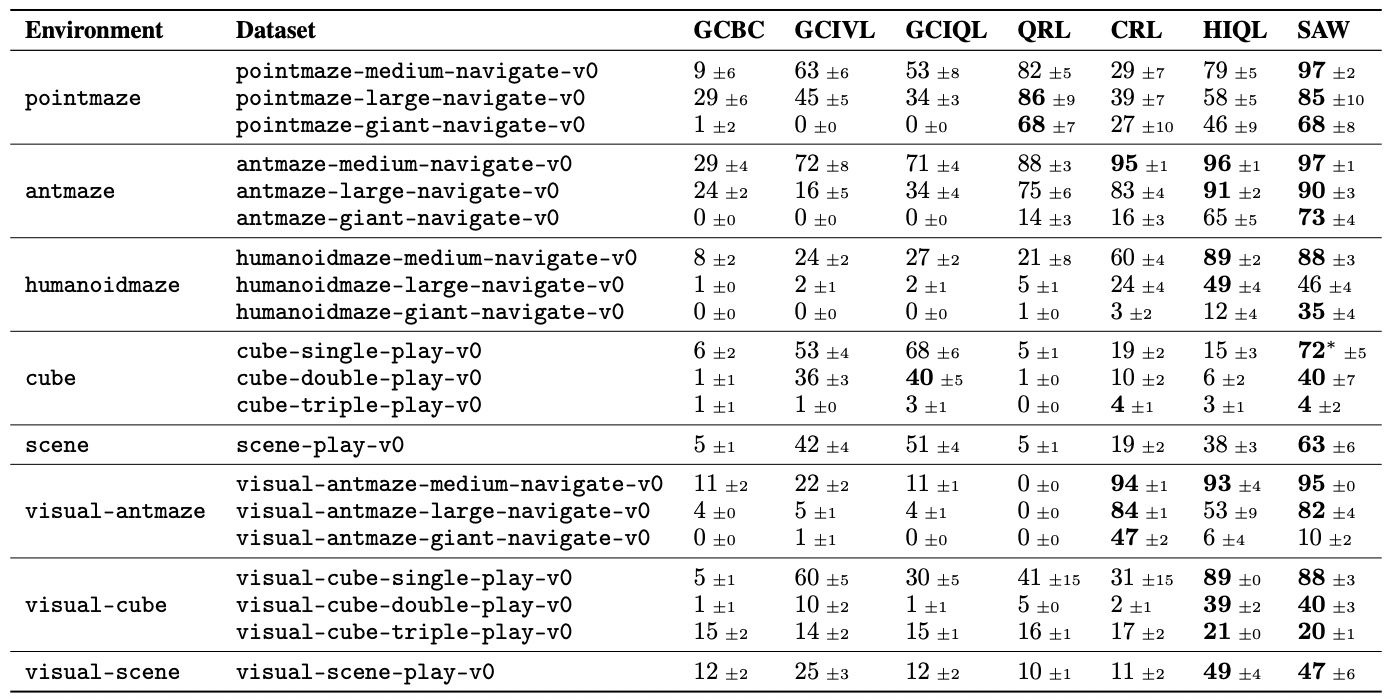
We evaluate SAW on a variety of locomotion and manipulation tasks from OGBench, showing state-of-the-art performance on nearly all tasks and outperforming hierarchical methods on the longest-horizon tasks: antmaze-giant-navigate-v0 and humanoidmaze-giant-navigate-v0 — being the first to achieve non-trivial performance on the latter!
Methods which generate subgoals often must predict in a compact latent space in order to scale to high-dimensional observation spaces. We find that one popular choice of sharing a representation between the goal-conditioned value function and the policy significantly harms SAW's performance and emphasizes a fundamental tradeoff in hierarchical methods: subgoal representations are essential for making high-level policy prediction tractable, but those same representations can constrain policy expressiveness and limit overall performance.